
Rilevamento ed Estrazione del Testo da un'Immagine con Python
Tecnica OCR e OpenCV per trovare il testo in un'immagine digitale
Questo articolo ti darà una panoramica sull'estrazione del testo dalle immagini digitali. Utilizzeremo Python e la libreria pytesseract per estrarre il testo. L'immagine dovrebbe contenere del testo al suo interno per ottenere il testo di output.
L'estrazione del testo con pytesseract richiede l'installazione di alcune librerie nell'ambiente di sistema. I seguenti comandi aiuteranno nell'installazione delle librerie nel tuo sistema.
Per installare la libreria OpenCV
pip install opencv-pythonPer installare la libreria pytesseract-ocr
pip install pytesseractPuoi anche scaricare il file di configurazione di Tesseract da questo link:
https://github.com/UB-Mannheim/tesseract/wikiScarica il file sopra in base alla configurazione del sistema e successivamente installalo. Vedremo il file tesseract.exe nel percorso indicato di seguito:
C:\Program Files\Tesseract-OCR\tesseract.exe"Osserviamo l'immagine di input da cui dobbiamo estrarre il testo.

In questo esempio Python, estrarremo il testo dall'immagine in scala di grigi, e nel prossimo esempio, estrarremo il testo da un'immagine a colori con una bounding box.
Estrazione del testo da un'immagine in scala di grigi
Dobbiamo importare tutte le librerie necessarie per questo esempio.
from PIL import Image
from pytesseract import pytesseractOra utilizzeremo la libreria Pillow per aprire/leggere l'immagine.
image = Image.open('ocr.png')
image = image.resize((400,200))
image.save('sample.png')Osservazioni:
- Il metodo `open` viene utilizzato per leggere l'immagine dalla directory di lavoro.
- Il metodo `resize` viene utilizzato per cambiare le dimensioni dell'immagine.
- Il metodo `save` viene utilizzato per salvare l'immagine dopo averne cambiato le dimensioni.
Ora definiremo il percorso del file binario di Tesseract come mostrato di seguito.
path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
pytesseract.tesseract_cmd = path_to_tesseractÈ ora di utilizzare il metodo `image_to_string` della classe Tesseract per estrarre il testo dall'immagine.
text = pytesseract.image_to_string(image)
#print the text line by line
print(text[:-1])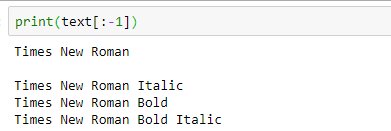
Rilevamento ed estrazione del testo da un'immagine a colori
In questa sezione, estrarremo il testo da un'immagine a colori. L'immagine a colori di esempio è mostrata di seguito.

In questo esempio, utilizzeremo anche OpenCV per utilizzare la bounding box e altri metodi di OpenCV.
Installiamo le librerie per questo esempio.
import cv2
from pytesseract import pytesseractOra definiremo il percorso del file binario di Tesseract come mostrato di seguito.
path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
pytesseract.tesseract_cmd = path_to_tesseractLeggiamo l'immagine con l'aiuto del metodo OpenCV.
img = cv2.imread("color_ocr.png")Convertiamo l'immagine a colori in un'immagine in scala di grigi per un miglior processamento del testo.
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)Ora convertiremo l'immagine in scala di grigi in un'immagine binaria per migliorare la possibilità di estrazione del testo.
ret, thresh1 = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU |
cv2.THRESH_BINARY_INV)
cv2.imwrite('threshold_image.jpg',thresh1)Qui, il metodo imwrite viene utilizzato per salvare l'immagine nella directory di lavoro.

Per ottenere le dimensioni delle frasi o anche di una parola dall'immagine, abbiamo bisogno di un metodo di elemento di struttura in OpenCV con la dimensione del kernel che dipende dall'area del testo.
rect_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (12, 12))Il passo successivo è utilizzare il metodo di dilatazione sull'immagine binaria per ottenere i contorni del testo.
dilation = cv2.dilate(thresh1, rect_kernel, iterations = 3)
cv2.imwrite('dilation_image.jpg',dilation)
Possiamo aumentare il numero di iterazioni, a seconda dei pixel in primo piano, ovvero i pixel bianchi, per ottenere la forma corretta della bounding box.
Adesso, utilizzeremo il metodo `findContours` per ottenere l'area dei pixel bianchi.
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_NONE)Per effettuare alcune operazioni sull'immagine, copiamola in un'altra variabile.
im2 = img.copy()Adesso, è il momento che accada la magia sull'immagine. Qui otterremo le coordinate dell'area del pixel bianco e disegneremo la bounding box attorno ad essa. Salveremo anche il testo dall'immagine nel file di testo.
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# Disegna la bounding box sull'area del testo
rect=cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Ritaglia l'area della bounding box
cropped = im2[y:y + h, x:x + w]
cv2.imwrite('rectanglebox.jpg',rect)
# Apri il file di testo
file = open("text_output2.txt", "a")
# Utilizzando tesseract sull'area dell'immagine ritagliata per ottenere il testo
text = pytesseract.image_to_string(cropped)
# Aggiungi il testo al file
file.write(text)
file.write("\n")
# Chiudi il file
file.closeL'output dell'immagine della bounding box.

Il risultato del file di testo.
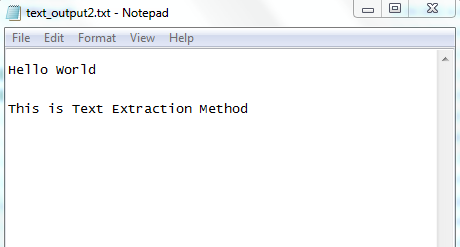
Abbiamo notato una cosa: quando il numero di iterazioni è pari a 1, il testo non viene salvato nel file di testo. Dopo aver aumentato il numero di iterazioni a 3, abbiamo ottenuto i risultati.
Se il codice funziona correttamente e l'output non viene visualizzato, controlla o cambia la dimensione del kernel e il numero di iterazioni.
Per estrarre l'immagine di ciascuna bounding box dall'immagine.
crop_number=0
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# Disegna la bounding box sull'area del testo
rect = cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Ritaglia l'area della bounding box
cropped = im2[y:y + h, x:x + w]
cv2.imwrite("crop"+str(crop_number)+".jpeg",cropped)
crop_number+=1
cv2.imwrite('rectanglebox.jpg',rect)
# Apri il file di testo
file = open("text_output2.txt", "a")
# Utilizzando tesseract sull'area dell'immagine ritagliata per ottenere il testo
text = pytesseract.image_to_string(cropped)
# Aggiungi il testo al file
file.write(text)
file.write("\n")
# Chiudi il file
file.close
Spero che l'articolo ti sia piaciuto. Contattami sul mio LinkedIn e Twitter.
Articoli Consigliati
1. 8 Approfondimenti sull'Apprendimento Attivo del Modulo di Raccolta di Python 2. NumPy: Algebra Lineare su Immagini 3. Concetti di Gestione delle Eccezioni in Python 4. Pandas: Gestione dei Dati Categorici